Elixir の Elixir による Elixir のためのログ解析
これは?
こんにちは。YAMAP 分析チームの松本です。
これは Elixir Advent Calendar 2020 23日目の記事です。 昨日は @g_kenkun さんの Elixirで他人に扱われるプログラムを書くときに考える例外の話 でした。
私が Elixir が好きな理由の一つは、パターンマッチとエラーハンドリング機構により、正常処理と例外処理を分離してコードの可読性を高めることが出来る点で、興味深く読ませて頂きました 🙏
さらに YAMAP エンジニア Advent Calendar 2020 24日目の記事でもあります。
さて自分の記事はというと、YAMAP の画像アップロードサービス を Elixir/Phoenix でリニューアルして2年経つので、その振り返りをしてみようと思いました。
画像アップロードサービス については↓で紹介しています。
何を振り返るか
振り返りの題材としては、以下にしようと思います。
- YAMAP の MAU、活動日記数 の成長
- それに従い、画像アップロードサービスはどうスケールしたか?
YAMAP の MAU、活動日記数 の成長
こちらの記事の通り、2019-10 vs 2020-10 で以下の成長となっています。
- MAU 160%
- 活動日記数 220%
画像アップロードサービスのスケール指標をどう定義するか
先のスライドにもある通り、画像アップロードサービスは AWS ECS クラスタ上で動いています。 なので単純に起動しているコンテナ数を、スケールの指標とできそうです。
Phoenix が出力するログ(カスタマイズしてます)には、コンテナの ID か IP かを記録していた気がします。 例えば5分ごとのコンテナの IP のユニーク数を集計すれば、5分ごとに何台のコンテナが起動していたかが分かります。 YAMAP ではサーバーのログは BigQuery に転送しているので、シュッと集計できます。簡単簡単。
...そう思っていた時期が、俺にもありました。

Phoenix のログを諦めて ALB のログを調べる
Phoenix のログ(カスタマイズしてます)に、コンテナを識別する情報が無かった
はい、ございませんでした。涙目です😭
CloudWatch のメトリクスにあってくれぇ!と望みをかけましたが、コンテナ数に相当するものは見つけられませんでした。
ALB ログで何とかする
と、ここで ALB(Application Load Balancer)のログを取っていることを思い出し、調べてみるとリクエストを処理した後段の IP とポートが記録されていました。

ECS では ALB から後段のサービス(コンテナ)に、動的ポートマッピングで接続しています。 なのでこの target:port が、コンテナを識別する情報とできそうです。
ALB ログを解析する
ちょちょっと Phoenix のログを分析して終わりのはずが、やることが増えてしまいました...
とりあえず以下をやらなくてはいけません。
- ALB ログをダウンロードして、
- パースして必要な情報を抽出し、
- 5分ごとのコンテナ数を可視化する
実装一式、↑に up しました。
1. ALB ログをダウンロード
alb_log_sandbox/download_log.sh at master · hidetaka-f-matsumoto/alb_log_sandbox · GitHub
指定日のログを aws s3 cp コマンドで取ってきて gzip 回答しています。
2. パースして必要な情報を抽出
alb_log_sandbox/alb_log.ex at master · hidetaka-f-matsumoto/alb_log_sandbox · GitHub
先の ALB のログフォーマットに従い、ログ1行を正規表現でパースするモジュールを作りました。
alb_log_sandbox/alb_log_sandbox.ex at master · hidetaka-f-matsumoto/alb_log_sandbox · GitHub
こちらは 1 でダウンロードした大量のログファイルを一括パースして、必要な情報を csv 1ファイルに出力するモジュールです。
Flow で多量のログファイルを並列処理している点が、Elixir らしいポイントかと思います。
def convert_log_to_request_csv(src_dir, dst_file, pattern) do Path.wildcard("#{src_dir}/*.log") |> Flow.from_enumerable(max_demand: 20) |> Flow.flat_map(fn path -> parse_log(path) |> select_by_pattern(pattern) end) |> Enum.to_list |> output_request_csv(dst_file) end
実際ここで並列処理することで CPU のコアも使い切り、体感で倍くらい早く処理が終わりました。

3. 5分ごとのコンテナ数を可視化する
最後にコンテナ数を可視化します。
2 でリクエスト時刻 time, 処理した後段の IP:PORT target を csv に出力しているので、5分毎の target のユニーク数を可視化してみます。
今回は Elixir と同じくパイプ演算子を持つ R 言語でやってみます。
R のパイプは %>% です。
alb_log_sandbox/visualize_target_count.R at master · hidetaka-f-matsumoto/alb_log_sandbox · GitHub
library(tidyverse) library(lubridate, warn.conflicts = FALSE) args <- commandArgs(trailingOnly=TRUE) data <- read_csv(args[1]) data %>% mutate(time_group = round_date(data$time, '5 mins')) %>% group_by(time_group) %>% summarize(target_count = n_distinct(target)) %>% ggplot(mapping = aes(x = time_group, y = target_count)) + layer(geom = "bar", stat = "identity", position = "identity")
たったこれだけでデータの集約と、グラフの描画ができるのは良いですね。 パイプ演算子により、コードの可読性も高まっていると感じます。
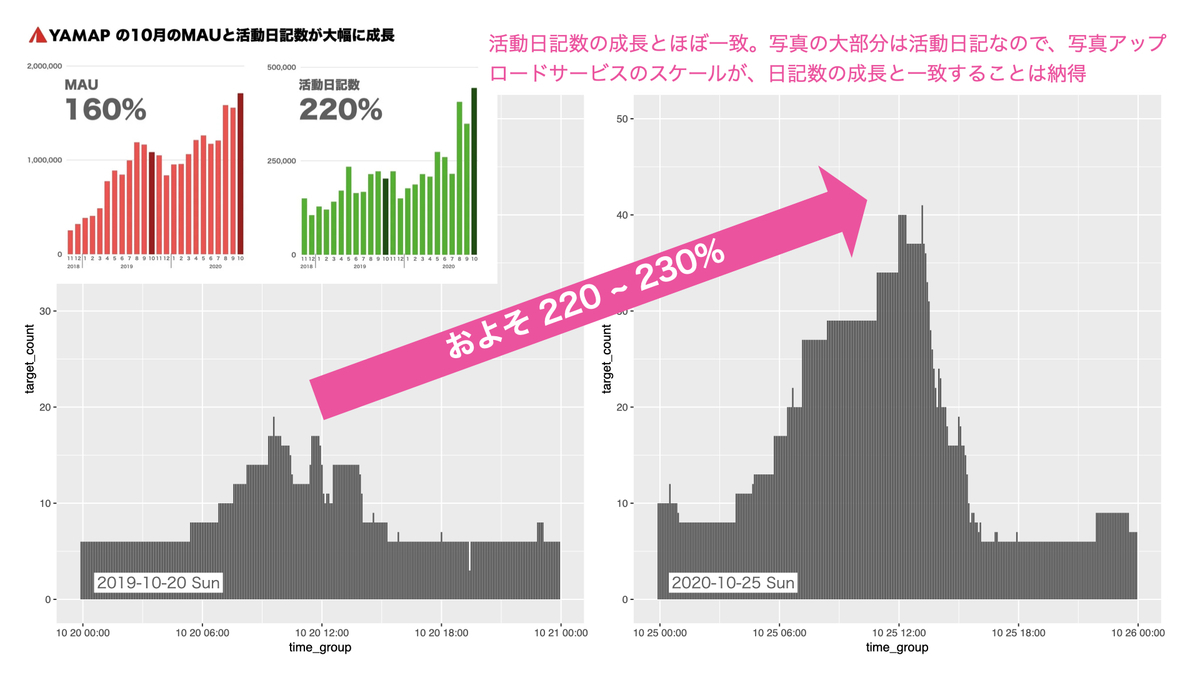
そして可視化してみた結果は、画像アップロードサービスは 2019-10-20 vs 2020-10-25 で 220 ~ 230% 程度スケールしていました。 これは活動日記数の成長と一致しており、自然な結果と考えられます。
※グラフの時間軸は UTC になっていますmm
まとめ
以上、いかがでしたでしょうか。 最初は優雅に Phoenix サービスのスケール状況を分析しつつ、何か Elixir ならではの特徴が見えないかなぁとか考えていましたが、甘かったですね...
蓋を開けてみると想定外にモリモリ実装する羽目になり、何のアドベントカレンダーなんだか分からなくなってしまいました😅
しかしログのパースなどは Elixir のパターンマッチの強みを活かせる好例ですので、その周辺の紹介が多少なりできなのは良かったかもしれません。 駆け足で実装したので綺麗なコードとは言いがたいかもしれませんが、何かしら皆様の参考になる箇所があれば幸いです。
それではまた。