Embulkでjsonb型カラムを転送するときは、DB側でキャストして高速化
はじめに
YAMAP エンジニアのカレンダー | Advent Calendar 2022 - Qiita 17日目の記事です。
YAMAP の業務でも使わせて頂いているバルクデータローダー Embulk について、データベースの jsonb 型カラムを扱う際の高速化 Tips を書きます。
jsonb 型カラムを Postgres 側で text にキャストして劇的高速化
YAMAP アプリケーションのメインの DB は Postgres でデータ基盤は BigQuery で、日々多くのテーブルを Embulk で Postgres -> BigQuery へと転送しています。 その中のあるテーブルは jsonb 型のカラムを持ち、レコード数も膨大で、転送には9時間ほどかかっていました。
そんなある日、Embulk が jsonb 型カラムの値のパースに失敗したエラーを吐きました。
MessagePack cannot serialize BigInteger larger than 2^64-1
確認すると確かに1つのレコードの json の中に、64bit int を超える値が含まれていました。
どうしたもんかな... と悩みましたが、「そもそも BigQuery には string 型で格納されるわけだし、わざわざ MessagePack にシリアライズさせず、Postgres にやらせればよいのでは」と思いたち、そうしてみました。
従来のクエリ
SELECT col1, col2, col_json FROM some_table;
修正後のクエリ
SELECT col1, col2, col_json::text FROM some_table;
すると目論見通りエラーは解消できたのですが、なんと従来9時間かかっていた転送が、6時間程度で終わるようになったではありませんか!
確かに MessagePack では先のエラーが示すように細かなバリデーションの分時間がかかりそうだし、そもそも Embulk の実行環境より Postgres の環境の方がコンピューティングリソースが豊富です。 この結果は納得ができます。
手元でも検証してみた
このサンプルでは、ネットで拾ってきたサンプル json を使い、1万行の初期データを用意しています。 それを Embulk 側でシリアライズする場合と、Postgres 側でする場合(text 型へのキャストを指定)で、実行時間を比較ます。
Embulk 側でシリアライズする場合(キャスト指定なし)
docker-compose run --rm \
-e EMBULK_CONFIG=pg_to_csv \
-e PG_QUERY='SELECT id, body FROM json_samples' \
embulk
real 0m3.978s
user 0m9.468s
sys 0m0.684s
Postgres 側でシリアライズする場合(キャスト指定あり)
docker-compose run --rm \
-e EMBULK_CONFIG=pg_to_csv \
-e PG_QUERY='SELECT id, body::text FROM json_samples' \
embulk
real 0m3.582s
user 0m7.907s
sys 0m0.505s
数回実行してみましたが、安定して1秒程度の差がありました。 1万行のデータだけでも結構な差を確認できました。
おわりに
これまでに幾度も Embulk の高速化のために戦ってきましたが、最も費用対効果の高かったのがこれですw
jsonb 型カラムのある巨大テーブルでのみ役に立つニッチな Tips ですが、あと 2, 3 人は困ってる人いるのでは。届けこの想い 🕊️
僕が欲しい革新的サービス2選
こんにちは。YAMAP アドベントカレンダー 18日目の記事です。 前回は issyxissy さんの GAS のトリガーでエラー検知を工夫してみた でした。
今日は技術ネタを書く気力がないので、前から欲しいと思っている革新的サービスについて書こうと思います。(ゴメンよ)
カップ麺用替え玉

YAMAP は博多に本社があるので、みんな豚骨ラーメンが好き(なはず)です。 僕も好きです。 今の御時世、スーパーやコンビニでもとても美味しいカップ麺が打っています。 カップ麺にしては若干高いですが。 そしてコストの問題でしょうか、そういうやつの麺は若干少ない気がします。
このペインを解決するのが、カップ麺用替え玉です。
一杯目が終わった後、お湯で戻して残スープに追加するのも良いですし、最初から投入して大盛りにすることもできるでしょう。 素晴らしいではないか。
ピッチングセンター

僕は本格的にやったことはないですが、野球をやるのが好きです。 そのうち草野球チームに入りたいとも思っています。
街にバッティングセンターってのは沢山ありますが、ピッチングが出来る施設は無いですよね。 稀にバッティングセンターの隅の方にストラックアウトがありますが、普通に面白くなかった記憶があります。 やはり放るなら打ち返してくれなくては手応えがない。
そのニーズに応えるのが、ピッチングセンターです。
バッティングマシーン(そんなもんあるのか)と1対1の熱い勝負です。 友達とやれよと言う方もいるでしょうが、友達がいないんです。無茶言わんで下さい。
ところで↑のイラスト屋さんの素材、僕にはブンブン丸こと池山選手に見えるのですが、皆さんはどうでしょう?
おわりに
クソ記事にも関わらずここまで読んでくれたあなたは優しい人です。 グラッツェ!
Elixir の Elixir による Elixir のためのログ解析
これは?
こんにちは。YAMAP 分析チームの松本です。
これは Elixir Advent Calendar 2020 23日目の記事です。 昨日は @g_kenkun さんの Elixirで他人に扱われるプログラムを書くときに考える例外の話 でした。
私が Elixir が好きな理由の一つは、パターンマッチとエラーハンドリング機構により、正常処理と例外処理を分離してコードの可読性を高めることが出来る点で、興味深く読ませて頂きました 🙏
さらに YAMAP エンジニア Advent Calendar 2020 24日目の記事でもあります。
さて自分の記事はというと、YAMAP の画像アップロードサービス を Elixir/Phoenix でリニューアルして2年経つので、その振り返りをしてみようと思いました。
画像アップロードサービス については↓で紹介しています。
何を振り返るか
振り返りの題材としては、以下にしようと思います。
- YAMAP の MAU、活動日記数 の成長
- それに従い、画像アップロードサービスはどうスケールしたか?
YAMAP の MAU、活動日記数 の成長
こちらの記事の通り、2019-10 vs 2020-10 で以下の成長となっています。
- MAU 160%
- 活動日記数 220%
画像アップロードサービスのスケール指標をどう定義するか
先のスライドにもある通り、画像アップロードサービスは AWS ECS クラスタ上で動いています。 なので単純に起動しているコンテナ数を、スケールの指標とできそうです。
Phoenix が出力するログ(カスタマイズしてます)には、コンテナの ID か IP かを記録していた気がします。 例えば5分ごとのコンテナの IP のユニーク数を集計すれば、5分ごとに何台のコンテナが起動していたかが分かります。 YAMAP ではサーバーのログは BigQuery に転送しているので、シュッと集計できます。簡単簡単。
...そう思っていた時期が、俺にもありました。

Phoenix のログを諦めて ALB のログを調べる
Phoenix のログ(カスタマイズしてます)に、コンテナを識別する情報が無かった
はい、ございませんでした。涙目です😭
CloudWatch のメトリクスにあってくれぇ!と望みをかけましたが、コンテナ数に相当するものは見つけられませんでした。
ALB ログで何とかする
と、ここで ALB(Application Load Balancer)のログを取っていることを思い出し、調べてみるとリクエストを処理した後段の IP とポートが記録されていました。

ECS では ALB から後段のサービス(コンテナ)に、動的ポートマッピングで接続しています。 なのでこの target:port が、コンテナを識別する情報とできそうです。
ALB ログを解析する
ちょちょっと Phoenix のログを分析して終わりのはずが、やることが増えてしまいました...
とりあえず以下をやらなくてはいけません。
- ALB ログをダウンロードして、
- パースして必要な情報を抽出し、
- 5分ごとのコンテナ数を可視化する
実装一式、↑に up しました。
1. ALB ログをダウンロード
alb_log_sandbox/download_log.sh at master · hidetaka-f-matsumoto/alb_log_sandbox · GitHub
指定日のログを aws s3 cp コマンドで取ってきて gzip 回答しています。
2. パースして必要な情報を抽出
alb_log_sandbox/alb_log.ex at master · hidetaka-f-matsumoto/alb_log_sandbox · GitHub
先の ALB のログフォーマットに従い、ログ1行を正規表現でパースするモジュールを作りました。
alb_log_sandbox/alb_log_sandbox.ex at master · hidetaka-f-matsumoto/alb_log_sandbox · GitHub
こちらは 1 でダウンロードした大量のログファイルを一括パースして、必要な情報を csv 1ファイルに出力するモジュールです。
Flow で多量のログファイルを並列処理している点が、Elixir らしいポイントかと思います。
def convert_log_to_request_csv(src_dir, dst_file, pattern) do Path.wildcard("#{src_dir}/*.log") |> Flow.from_enumerable(max_demand: 20) |> Flow.flat_map(fn path -> parse_log(path) |> select_by_pattern(pattern) end) |> Enum.to_list |> output_request_csv(dst_file) end
実際ここで並列処理することで CPU のコアも使い切り、体感で倍くらい早く処理が終わりました。

3. 5分ごとのコンテナ数を可視化する
最後にコンテナ数を可視化します。
2 でリクエスト時刻 time, 処理した後段の IP:PORT target を csv に出力しているので、5分毎の target のユニーク数を可視化してみます。
今回は Elixir と同じくパイプ演算子を持つ R 言語でやってみます。
R のパイプは %>% です。
alb_log_sandbox/visualize_target_count.R at master · hidetaka-f-matsumoto/alb_log_sandbox · GitHub
library(tidyverse) library(lubridate, warn.conflicts = FALSE) args <- commandArgs(trailingOnly=TRUE) data <- read_csv(args[1]) data %>% mutate(time_group = round_date(data$time, '5 mins')) %>% group_by(time_group) %>% summarize(target_count = n_distinct(target)) %>% ggplot(mapping = aes(x = time_group, y = target_count)) + layer(geom = "bar", stat = "identity", position = "identity")
たったこれだけでデータの集約と、グラフの描画ができるのは良いですね。 パイプ演算子により、コードの可読性も高まっていると感じます。
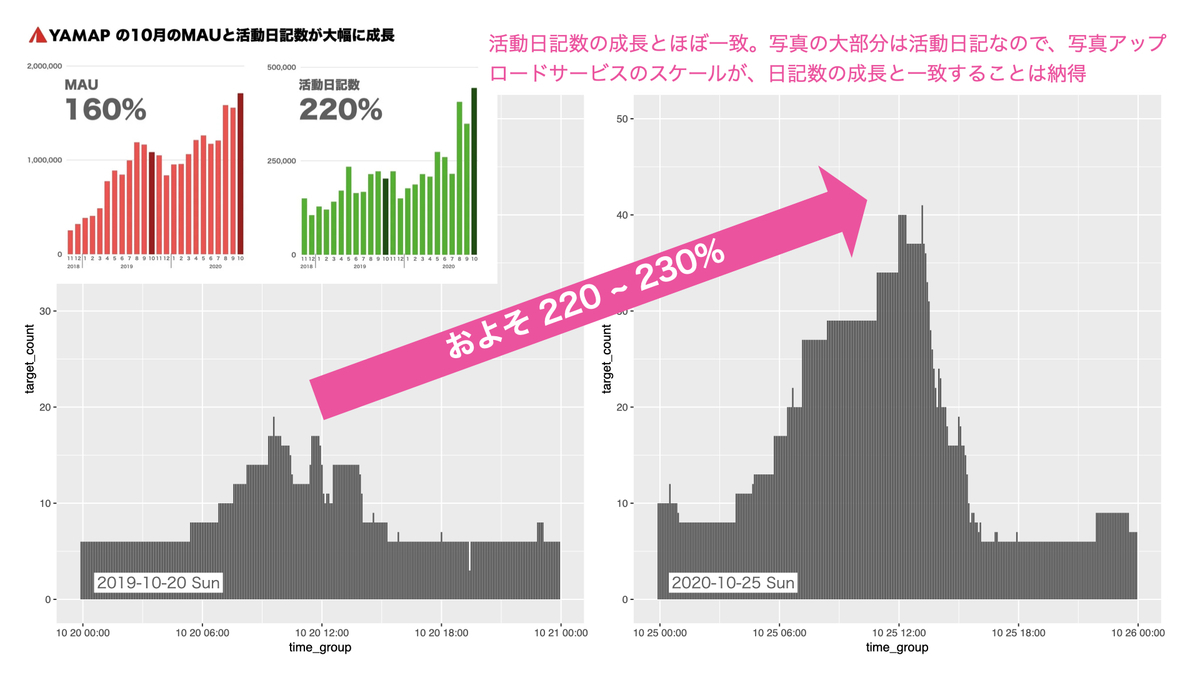
そして可視化してみた結果は、画像アップロードサービスは 2019-10-20 vs 2020-10-25 で 220 ~ 230% 程度スケールしていました。 これは活動日記数の成長と一致しており、自然な結果と考えられます。
※グラフの時間軸は UTC になっていますmm
まとめ
以上、いかがでしたでしょうか。 最初は優雅に Phoenix サービスのスケール状況を分析しつつ、何か Elixir ならではの特徴が見えないかなぁとか考えていましたが、甘かったですね...
蓋を開けてみると想定外にモリモリ実装する羽目になり、何のアドベントカレンダーなんだか分からなくなってしまいました😅
しかしログのパースなどは Elixir のパターンマッチの強みを活かせる好例ですので、その周辺の紹介が多少なりできなのは良かったかもしれません。 駆け足で実装したので綺麗なコードとは言いがたいかもしれませんが、何かしら皆様の参考になる箇所があれば幸いです。
それではまた。
Looker + hubot によるデータ業務の自動化
はじめに
🔺YAMAP 分析チームの松本です。 Looker Advent Calendar 2020 兼 YAMAP エンジニア Advent Calendar 2020 3日目の記事です。 よろしくお願いします。
YAMAP では登山地図の情報をより充実・正確にするために、ユーザーデータを活用した 伊能忠敬プロジェクト に取り組んでいます。 具体的な一例としては、ユーザーさんの軌跡を分析して新規ルートを抽出し、登山地図に反映しています。
このルート抽出処理は Python で実装しており、従来は分析者が手元のマシンで実行していました。 また、地図上のどこに対してルート抽出を試みるかは、データ基盤のデータを Looker で可視化して決めています。

今夏にはじめたルート抽出の取り組みも軌道に乗り、最近では自動化・効率化の機運が高まっていました。
どう自動化するか
Python ルート抽出処理については、もともと運用していた分析システム(Python / GKE)に組み込みました。 あとは Looker のデータから抽出処理を kick する所を自動化すれば OK ですが、ここでは 2 つの方法を検討しました。
- Looker Action Hub でカスタムアクションを開発する
- Looker から Slack へ抽出候補 csv を投稿させる。hubot で csv を読み取り、抽出処理を kick する
今回は以下の理由から、2 の方法を採用しました。
- 自動化の仕組みから GKE クラスタに対して kubectl コマンドを実行するため ※1
- ルート抽出処理の kick は k8s job をデプロイする形で行いたく、そのために kubectl コマンドで実行したかった
- これは 1 の方法では実現できなさそうに思われた
- 一連のオペレーションは人間が ChatOps として実行できるようにもしておきたかったため
- YAMAP ではユーザーさんからルート追加要望を承る場合もあり、その場合はオペレーターがルート抽出を kick できると便利
ということで、以下のような構想になります。

自動化した結果
- hubot の名前は "yak" にしました。ヤクはヒマラヤ地方の高地に生息する牛さんです
- Looker から csv をスケジュール配信します。コメントに hubot のコマンドを書いておきます
- yak がファイルをパースして、kubectl コマンドでルート抽出処理を kick します
- 分析システム(yama)が処理完了を教えてくれます

- この後、地図エディタで成果物を人間がチェックして、登山者の皆様にお届けしています



やったね 🎉
まとめと展望
Looker + hubot で、YAMAP 伊能忠敬プロジェクトのオペレーションの一部を自動化しました。 Looker には Action Hub という便利な仕組みも用意されていますが、今回のように事情がある場合は hubot などチャットボットを利用することが出来ます。
今回は僕が所属する分析チームのオペレーションを自動化しましたが、今後は hubot や Action Hub も活用して社内のデータ業務を自動化し、データ活用を加速したいと思います。
それにしても YAMAP では様々なデータ活用が広がっており、それを柔軟に支えてくれる Looker は本当に素晴らしいツールだと思います! (hubot アドベントカレンダーみたいになってしまいスミマセンでした 😅)
実装(ご参考まで)
何もコードがないのは寂しいので、hubot の yama extract-route コマンドの正常系の実装だけ載せておきます。
'use strict'; const util = require('util'); const childProcess = require('child_process'); const exec = util.promisify(childProcess.exec); const fs = require('fs'); const csv = require('csv'); const request = require('request'); module.exports = (robot) => { robot.respond(/yama extract-route/i, async (res) => { const fileInfo = res.message.rawMessage.files[0], tmpFilePath = `tmp/${fileInfo.timestamp}_${fileInfo.name}`; let data = []; const parser = csv.parse((err, row) => { data = row; }); request .get(fileInfo.url_private_download) .auth(null, null, true, process.env.HUBOT_SLACK_TOKEN) .pipe(fs.createWriteStream(tmpFilePath)) .on('finish', () => { fs.createReadStream(tmpFilePath) .pipe(parser) .on('end', async () => { // process head 10 rows. for (let row of data.slice(1, 4)) { const result = await exec(`LANDMARK=${row[1]} k8s/scripts/deploy/run_route_extraction`); res.send(result.stdout); } }); }); }); }
補足
今回採用しなかった Looker Action Hub を改めて調べると、GCP の CloudStorage に csv を PUT するアクションが用意されていました。
CloudStorage の PUT イベントに対して CloudFunction をトリガすることで、※1 はクリアできる可能性があることに、この記事を書きながら気づきました...
Elixir/Phoenix + Neo4j でお手軽!高速!経路探索
はじめに
聖夜に fukuoka.ex Elixir/Phoenix Advent Calendar 2019 兼 YAMAP エンジニア Advent Calendar 2019 24日目の記事がやって参りました🎅
🔺YAMAP 分析チームの松本です。元バックエンドエンジニアです。
YAMAP のバックエンドでは、応答速度やスケーラビリティの性能が要求されるケースでの選択肢として、Elixir/Phoenix を活用しています。
また従来より YAMAP では、登山計画時の便利機能として、経路探索システムが熱望されていました。
今回は
- グラフ構造をもつデータの探索を得意とする GraphDB Neo4j
- 応答速度に優れる Elixir/Phoenix
- 特に理由はないけどフロントは Elm
を利用し、お手軽かつ高速な経路探索システムを開発してみようと思います。
Neo4j とは
実は僕は詳しくなくて、SNS での人間関係の探索などに使われる DB くらいのイメージです。 「A さんは最近サーフィンに興味があるので、友達の友達の範囲内で、サーフィンが趣味の人をサジェストする」等
経路もグラフ構造なので、経路探索にも向いているようです。
Elixir/Phoenix とは
特に説明不要かと思いますが、詳しくはこいつを見てくれ。
すごく
- 省リソースで
- 耐障害性が高くて
- 応答速度が早い
です。
問題設定
今回やることを定義します。 経路探索の舞台は、我らが「宝満山」にします。(福岡県)

↑地図の通り、
- Neo4j
- n0 ~ 19 までの node を設定する
- 実際の登山道に基づき、node 間の relationship を定義する(コースタイムも)
- Elixir/Phoenix
- Elm
- 地図上に node を表示する
- 2点を選択したら経路探索を実行
- 結果のルートを表示する
が、今回やることです。
開発結果

始点と終点を選択すると、所要時間が短い順に、3つの経路がサジェストされます。 登山計画が捗る予感がする!🗻
開発詳細
Repository & Setup
Elixir/Phoenix
$ docker-compose build $ docker-compose up phoenix
すれば動くはず。
Neo4j
↑の後、localhost:7474 を開くと Neo4j コンソールが見れるので、初期ユーザー / パスワード = neo4j / neo4j でログインできます。
その後パスワードを password に変更します。(Phoenix の設定合わせ)
Elm
$ elm make src/App.elm --output src/app.js $ elm reactor --port=8002
すれば動くはず。 ちなみに僕はフロントも Elm も素人なんでクソコード勘弁して下さい😓
mix task で Neo4j にデータ投入
$ docker-compose run --rm phoenix mix import_seed_data
localhost:7474 で Neo4j のデータを確認すると、

宝満山の登山道のグラフ構造が確認できます。良いネ👍
データクリアしたい時は↓も用意してあります。
$ docker-compose run --rm phoenix mix clear_all_data
Neo4j 接続設定
Bolt.Sips を使いました。
config :bolt_sips, Bolt, url: "bolt://neo4j:7687", basic_auth: [username: "neo4j", password: "password"], pool_size: 10
検索実行
defmodule PhoenixNeo4jExample.Route do alias Bolt.Sips, as: Neo alias Bolt.Sips.Response alias Bolt.Sips.Types.Path alias Bolt.Sips.Types.Node ... def search(from, to) do query = cyper_query(:search, from, to) routes = Neo.conn() |> Neo.query!(query) |> parse_search_result {:ok, routes} end defp parse_search_result(%Response{records: records}) do records |> Enum.with_index |> Enum.map(fn({[_from, _to, %Path{nodes: nodes}, time], i}) -> %{ node_ids: Enum.map(nodes, fn(%Node{properties: %{"id" => id}}) -> id end), total_time: time, color: @colors |> Enum.at(i) } end) end defp cyper_query(:search, from, to) do ~s""" MATCH (from:Node {id: '#{from}'}), (to:Node {id: '#{to}'}), path=((from)-[walk:WALK_TO*1..10]->(to)) RETURN from, to, path, REDUCE(totalTime=0, w in walk | totalTime + w.time) as cost ORDER BY cost LIMIT 3 """ end ... end
Bolt.Sips は Cyper query の DSL は用意せず、生クエリを書いて query! 関数で実行するスタイルでした。
僕は DSL 好きじゃないので良いと思いました。
また Bolt.Sips.Response はかなりネストが深い構造でしたが、Elixir のパターンマッチで、割とスッキリ処理できました。
実は久しぶりに Elixir を書いたのですが、やっぱり書き味が素晴らしいです😊
まとめ
Elixir/Phoenix + Neo4j で、お手軽かつ高速な経路探索システムを開発しました。 実際どれくらいの応答速度になるのかは、データを大量に入れて検証していきたいと思います。
Elixir はパターンマッチが強力で、データ処理言語としても有用であることは、fukuoka.ex の @piacere さんも言われている 通りだと思います。
僕はバックエンド出身の分析エンジニアとして、分析処理した結果を api でユーザーに配信して〜といったシステムを作りたくなる時もあるのですが、Elixir/Phoenix は一つの良い選択肢だと考えています。 耐障害性に優れる点も、スタートアップ企業のような開発リソースが潤沢ではない局面で、とても助かるんですよね。
ということで、久しぶりに Elixir に触れて楽しいクリスマスイブでした! 達郎聴いて寝よ🎅🎸
Looker ノススメ
はじめに
Looker Advent Calendar 2019 兼 YAMAP エンジニア Advent Calendar 2019 1日目の記事です。 (元々 Qiita に書いていたもの を、こちらに引っ越しました)
こんばんは、🔺YAMAP 分析チームの松本です。好きな山は赤岳(八ヶ岳)です。 YAMAP は 2019-11 から、次世代 BI ツール Looker を導入しました。
この記事では、YAMAP で導入前に感じていた課題とその解決方法を中心に、Looker の素晴らしさを紹介したいと思います。
参考までに、YAMAP の概況
Looker をはじめ、 BI ツール導入を検討している方の参考になればと思い、会社の規模などを共有してみます。
Looker 導入前の課題と、どう解決するか
私達は、おおよそ以下のような課題を感じていました。

それがこうなります、Looker 凄い 🎉

以下でそれぞれ説明したいと思います。 なお LookML については、分かりやすくまとめて頂いている記事 等ありますので、そちらをご参照下さい 👀
a. データ基盤をみんなに使ってもらうには敷居が高い
私達は BigQuery にデータ基盤を構築し、2019-06 から運用を始めました。 (構築に当たっては 私の考えた最強のログ&モニタリング設計 - 下町柚子黄昏記 by @yuzutas0 がとても参考になりました。この場を借りてお礼を 🙏 )
ですがデータが1箇所に集まったのは良いものの、
- 何がどこにあるのか難易度が高く、分析者以外が使うのに敷居が高い
という課題がありました。
どう解決するか?
これは 「分析者が LookML を定義すれば、それを元に Looker が UI が提供してくれるので、利用者はポチポチでグラフが作れる」 という特徴により、解決できます。
b. Redash でクエリが乱立、メンテが大変
私達はもともと Redash を使っていました。 Redash は無料ですし、とても素晴らしかったのですが、運用を重ねるにつれ、
- 似たようなクエリが増殖
- どれが使われているのか分からない
- スキーマに変更があった際、参照しているクエリを修正して回るのが辛い
という課題が出てきました。
どう解決するか?
これも LookML が分析用 Object-relational mapping の如く、グラフとテーブルの間に入ってくれるので、テーブルに変更があったときは LookML を修正すれば、それを利用しているグラフを一括修正できる ということで解決できます。
また Looker には Look(グラフ) ごとのアクセス数を可視化する機能が備わっており、使われていない Look を整理するのにとても便利そうでした。
c. 人によってクエリの書き方が異なり、信頼性を担保しにくい
YAMAP では実際
- SQL を書く人の技量により、間違った集計を行ってしまう
- 技量が高くても分析対象のテーブルの細かい仕様までは把握しきれておらず、間違った集計を行ってしまう
といったケースが有りました。 (例えば、論理削除フラグや、契約履歴テーブルに "契約解除" でもレコードが挿入されるなどの仕様の把握漏れで、集計が水増しされてしまう. etc.)
こういう事が重なると、誰かがグラフを書いた時に「そもそも集計合ってるんだっけ?」といった確認作業が大変になるのも残念です。
どう解決するか?
これまた テーブル定義に精通した分析者が LookML を定義し、利用者はそれを使ってグラフを書く といった明確な分担ができることで、集計の信頼性が格段に担保しやすくなります。
d. 細かい集計依頼が多く、骨太な分析に時間を使えない
先に紹介したように、YAMAP は有料会員、登山保険、EC、営業と事業が多く、各チームから分析チームへ細かい集計依頼もコンスタントに来ています。
そして、YAMAP 分析チームは↓2つのミッションを掲げています。
- データ分析で事業の意思決定にコミットする
- ユーザーが投稿するデータを価値に変え、ユーザーに還元する
しかし先述したように現状分析チームは2人だけなので、各チームからの集計依頼が多くなると、2 に時間を使えなくなるという危機意識がありました。 (僕たちは 2 を "骨太な分析" と呼んでいます)
どう解決するか?
今まで書いたことでお分かり頂けると思うのですが、Looker は データの民主化 という視点で、とても強力です。 "LookML の定義に分析者が責任を持ち、利用者はそれを使ってグラフを書く" という切り分けができることで、データガバナンスとデータ民主化を両立できる 訳です。 今まで Looker を使ってみて、このバランス感は本当に素晴らしいと感じます 💜
ということで、Looker を各チームに浸透させ、簡単な集計や分析はチーム内で完結できるように持っていくことで、"骨太な分析" の時間も確保していく方針です。
加えて LookML はとても優秀で、クエリをかなり動的に生成してくれます。 故にお決まりの集計やデータ抽出業務は、グラフ(Look)の FILTERS パラメータを良い感じに用意してあげると、仕組み化しやすいです。 (Redash にもパラメータ機能はありますが、Looker はパラメータの選択状況に応じて JOIN 文レベルで切り替わってくれるので、柔軟に仕組み化できます)
まとめ
YAMAP での BI の課題と、それをどう解決できるのかを中心に、Looker をご紹介しました。
使えば使うほどに素晴らしいツールだと驚くのですが、特に
- "LookML の定義に分析者が責任を持ち、利用者はそれを使ってグラフを書く" という切り分けができることで、データガバナンスとデータ民主化を両立できる
点がミソなのかなと感じています。
しっかり使いこなして、みんなの登山をより安全にしていきたいと思います。 🗻 明日の Looker Advent Calendar 2019, YAMAP エンジニア Advent Calendar 2019 もお楽しみに!
うぐいすオルゴール (Nightingale Music Box)
App

デモソング (Demo song)
- アプリをインストール後に↓リンクをクリック (Click the bellow link after you install the App.)
- canon
操作方法 (How to)
- 音符を作る/消す (Create/delete a note.)
- テーブル上をタップ (Tap on the table.)
- オクターブを上げる/下げる (Up/down the octave.)
- テーブル上で左/右にスワイプ (Swipe on the table.)
- 曲の出来具合を確認する (Check the song you making.)
- テーブルを上/下にドラッグし、音を鳴らす (Play sounds by dragging the table.)
- 曲が完成したので再生する (Play your song.)
- 再生ボタンを押す (Tap the play button.)
